
A new, robust visual-language model aims to level up diagnostic AI in eye care…and beyond.
The coming shift to AI multimodal imaging analysis in ophthalmology just got another shot in the arm. EyeCLIP, a new visual-language model detailed in NPJ Digital Medicine, is the latest example of how artificial intelligence (AI) is advancing to tackle the complexities of eye disease diagnosis. It can detect not only common eye diseases, but also rare ones like Stargardt and macular telangiectasia. By combining imaging with clinical language, EyeCLIP sees what other models might be missing.1-3
So what exactly sets EyeCLIP apart?
A rising frontier in ophthalmology
EyeCLIP joins a growing list of multimodal AI tools aimed at eye care. RETFound, introduced in 2023, used self-supervised learning across modalities like OCT and fundus photography but maintained separate encoders. FLAIR, also released that year, focused on fundus images paired with expert-annotated text. While both models contributed important advancements, EyeCLIP researchers suggest their architectures may limit integration across modalities or broader generalization.1-3
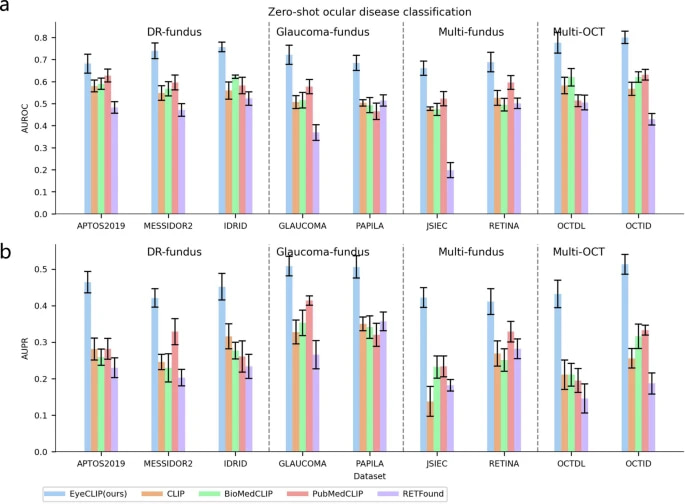
The EyeCLIP study suggests, at least, that it bridges those gaps. Its single-encoder design and joint image-text training purport to be a step toward more flexible, scalable solutions. Apart from outperforming domain-specific models like RETFound and FLAIR, EyeCLIP also demonstrated stronger performance than general-purpose medical models such as CLIP and PubMedCLIP across multiple tasks.1,4,5
READ MORE: AI in Ophthalmology: Maximizing Potential while Ensuring Data Safety
What is EyeCLIP and why it matters
EyeCLIP was trained on 2.77 million images across 11 ophthalmic imaging modalities—including OCT, fundus photography and angiography—alongside 11,000 clinical reports.1
Unlike earlier models that use separate encoders for different data types, EyeCLIP uses a single encoder to integrate both visual and textual data, enabling it to generalize across tasks and imaging sources.1
Its architecture blends three training strategies: self-supervised image reconstruction, image-to-image contrastive learning and image-to-text alignment. This training strategy is designed to help EyeCLIP not just see, but understand.1
READ MORE: Seeing the Unseen: Adaptive Optics Enters the Clinical Arena at ARVO 2025
Beyond classification, EyeCLIP pairs with large language models like Llama2-7b to enable visual question answering (VQA), connecting image findings to clinical queries. This capability supports applications in education, documentation and AI-assisted decision support in ophthalmology.1
It also performed well at cross-modal retrieval, effectively matching text and images in datasets like AngioReport and the Retina Image Bank. And if you’re wondering how EyeCLIP makes its calls, the model generates heatmaps that highlight key features—like optic nerve cupping in glaucoma or cherry-red spots in central retinal artery occlusion—so doctors can interpret the AI’s reasoning.1
Its design reflects a move toward AI tools that can adapt to varied clinical workflows, especially where data is complex or sparse.
READ MORE: Seeing the Unseen: Adaptive Optics Enters the Clinical Arena at ARVO 2025
Diagnostic performance
To test its abilities, EyeCLIP was benchmarked against existing models such as RETFound and FLAIR. Researchers evaluated its performance across various ophthalmic datasets and tasks, assessing how well its multimodal design held up.2,3
In the study, EyeCLIP was tested in “zero-shot” mode—meaning it attempted to classify diseases without specific task-based training—and compared to other models like RETFound and FLAIR. Across diabetic retinopathy, glaucoma and OCT-based tasks, EyeCLIP delivered strong performance, with Area Under the Curve (AUC) scores reaching up to 0.800.1
It also showed promising results in detecting rare diseases. On the Retina Image Bank, which includes 17 rare retinal conditions, EyeCLIP achieved higher AUROC scores than competing models. Even with limited training data (1–16 images), it performed well on conditions like Stargardt disease and macular telangiectasia.1
Beyond the eye, EyeCLIP demonstrated moderate performance in predicting systemic diseases—such as stroke, Parkinson’s and myocardial infarction—using retinal images from the UK Biobank, highlighting its potential cross-specialty applications.1
Limitations and future directions
The model was trained on data heavily concentrated in East Asian populations (primarily from nine Chinese provinces), and that raises questions about clinical generalizability to more diverse or underrepresented patient groups groups.1
Another challenge: EyeCLIP currently processes only 2D slices of inherently 3D imaging modalities like OCT and angiography. That may limit its ability to capture structural depth crucial for some diagnoses.1
To improve this, researchers aim to:
- Expand and diversify the dataset globally,
- Integrate full 3D imaging for richer insights,
- Optimize the model via quantization for clinical speed and efficiency, and
- Enhance interpretability tools to foster clinician trust.1
READ MORE: Is AI the Answer? Applications of AI in Ophthalmic Imaging Shows Significant Promise
If EyeCLIP findings hold up across larger and more diverse datasets, it could mark a shift in ophthalmic AI, from narrow, task-specific tools to more comprehensive systems capable of interpreting a wide range of imaging and clinical data.
As more research unfolds, this foundational model may help earlier disease detection, streamline clinical workflows and support more equitable diagnostics across populations and specialties.
Editor’s Note: This content is intended exclusively for healthcare professionals. It is not intended for the general public. Products or therapies discussed may not be registered or approved in all jurisdictions, including Singapore.
References
- Shi D, Zhang W, Yang J, et al. A multimodal visual–language foundation model for computational ophthalmology. NPJ Digit Med. 2025;8:381.
- Zhou Y, Chia MA, Wagner SK, et al. A foundation model for generalizable disease detection from retinal images. Nature. 2023;622(7981):156-163,
- Silva-Rodriguez J, Chakor H, Kobbi R, et al. A Foundation Language-Image Model of the Retina (FLAIR): Encoding expert knowledge in text supervision. Med Image Anal. 2025;99:103357.
- Radford A, Kim JW, Hallacy C, et al. Proceedings of the 38th International Conference on Machine Learning, PMLR. 2021;139:8748-8763.
- Zhang S, Xu Y, Usuyama N, et al. A Multimodal Biomedical Foundation Model Trained from Fifteen Million Image–Text Pairs. NEJM AI. 2025;2(1).